| Embedding | Sources | Chunking | Embedding | |
| Retrieval | Submission | Retrieval Engine |
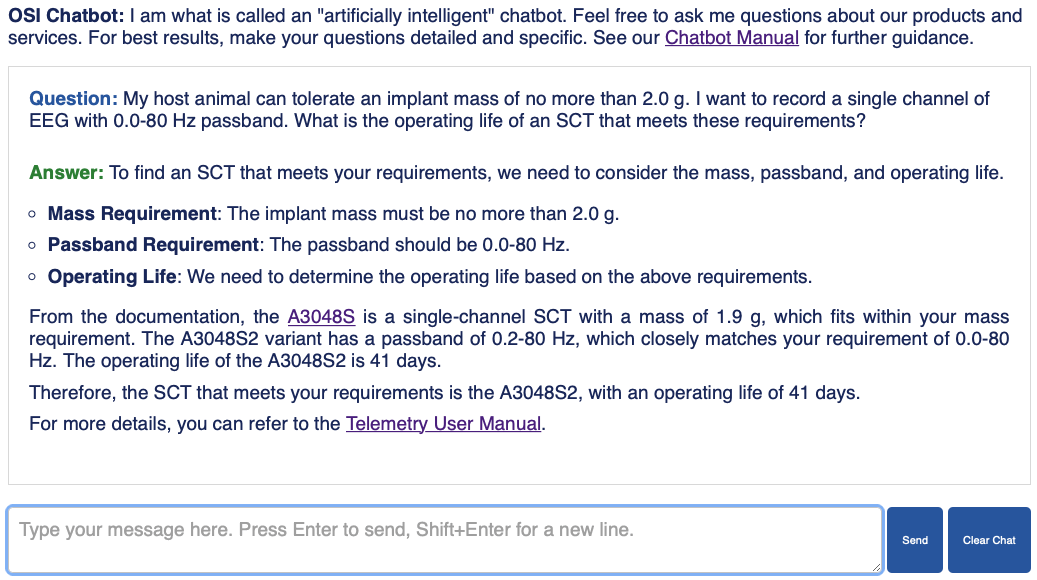
[26-MAY-26] The OSI Chatbot takes the user's question and uses it to select five or ten thousand words of documentation from its documentation library. It submits this documentation, along with the question, to a large language model (LLM) in order to obtain an answer, which it displays in the chatbot interface. The quality of the answer it provides depends upon whether or not the answer to the question is contained in the documentation the chatbot retrieved. In order to support the most effective retrieval of documentation, the question must be self-contained, specific, and detailed. If the question is vague, non-specific, or inaccurate, the retrieval will fail and it will be impossible for the LLM to provide a useful answer. The LLM has not been trained on the one million words of documentaiton in the OSI Chatbot's library, so the LLM cannot answer detailed questions about OSI's products and services without the assistance of documentation selected from the library. We call this type of answer generation retrieval-assisted generation or RAG.
The chatbot's documentation library consists of all the OSI website pages we think will be useful in answering customer questions. The content of the web pages is divided into fragments, each several hundred words long, which we call chunks. The chunks might consist only of prose, or they might be lists, tables, or figure captions. Many of them will include hyperlinks, and all of them have page and chapter titles. At the time of writing, there are roughly four thousand chunks in the library, making roughly one million words in all. Each time we enter a new question, the chatbot compares our question to all the chunks in its library. Based upon these comparisons, the chatbot measures how relevant our question is to the library. The chatbot answers high-relevance questions by selecting five thousand words of the most relevant documentation chunks and submitting them, along with the chat history and the question, to a heavy-weight LLM with advanced reasoning power, allowing up to sixty seconds for generation to complete. The chatbot answers mid-relevance questions by combining them with previous questions, if any exist, in the hope of generating a high-relevance question. Failing that, the chatbot submits the mid-relevance quesetion along with ten thousand words of documentation to a light-weight LLM to obtain an answer quickly. The chatbot answers low-relevance questions by immediately submitting the low-relevance question to a light-weight LLM without any documentation from the library at all. The idea is to have the light-weight LLM answer the question using its own built-in knowledge alone, this being more polite than refusing to answer the question on the grounds that it is irrelevant to the OSI products and services.
The OSI Chatbot performs well when the user types detailes and self-contained questions. A self-contained question provides all the information the chatbot needs to retrieve the information necessary to answer the question. The chatbot performs poorly when the questions are abbreviated, vague, and follow loosely upon previous questions. The chatbot saves all its questions and answers, along with the user's IP address, to daily log files on the OSI webserver. These log files allow us to monitor the performance of the chatbot. We see is a divide between users who take time to enter self-contained, accurate, and specific questions, and users who type ambiguous, error-filled, and non-specific questions. So we might see, "Explain how the system works," in place of "Explain how a LWDAQ system acquires images from BCAMs and transfers them to a computer." We might see "The transmitter system," in place of, "Describe how OSI's telemetry system works. What is the wireless protocol used for communication? How does the data acquistion computer communicate with the telemetry receiver?" In each case, the user assumes that the chatbot knows which system the user is talking about. The best we can do in response to such questions is ask for clarification. We have decided not to dedicate much effort to improving performance for vague questions, and instead focus on performance in response to well-worded questions.
The OSI Chatbot uses two LLM services: embedding and completion. In the embedding service, we pass a documentation chunk to an online embedding endpoint and the endpoint returns a list of numbers that represent the syntactic meaning of the chunk. We call this list of numbers the chunk's embed vector. In the completion service, we pass a string of text to an online completion endpoint, and the endpoint returns an answer. The completion endpoint does its best to complete the story begun by the documentation and the question. Because our submission to the completion endpoint begins with reference documentation, chat history, and instructions for how to answer a question, and then finishes with the question itself, the completion endpoint, in trying to complete the story told by our submission, will answer the question. The more detailed, self-consistent, and precise our question, the more accurate and useful the answer will be. In answering the question, the chatbot is quite capable of performing calculations and writing computer programs. It can display any photograph named in its documentation library. It will present measurements and calculations in graphical form if you ask it to do so. You may ask it to prepare tables that compare the various features of our products, or to provide specifications in the form of tables or lists.
[22-MAY-26] Here are some example questions that obtain complete and accurate answers from the chatbot.
Here are examples of questions that will receive poor answers. These questions are either innacurate, misleading, or unhelpful.
[26-MAY-26] The chatbot classifies each question as being of "high", "mid", or "low" relevance by comparing the question to our documentation library. The relevance of a question we obtain from the similarity between the question and the most similar chunk of documentation in our documentation library. The way we compare the syntactic meaning of paragraphs, captions, questions, and any other chunk of text is to obtain for the chunk an "embedding vector". We submit our documentation chunks one by one to an "embedding endpoint", and for each we obtain a unit vector in a high-dimensional space, which is the embedding vector. This we do at our leisure, and we save all the embedding vectors to disk, along with the content chunks themselves. The OSI chatbot uses the "text-embedding-3-small" endpoint, which returns a unit vector in a space of 1536 dimensions. The direction of the vector represents the syntactic meaning of the chunk. We take the dot product of the question's embedding vector with the embedding vector of each documentation chunk, and so obtain for each dot product the cosine of the angle between the two vectors. This cosine is our measurement of similarity. Similarity of 1.0 means identical meaning. Similarity of 0.0 means almost no similarity. We have never encountered a cosine less than zero, but in principle a similarity of −1.0 would be as opposite as one could get. The similarity of the most similar chunk is our measure of "relevance". The following parameters are all visible and adjustable in the Configuration Panel of the RAG Manager Tool.
set config(high_rel_thr) "0.55" set config(mid_rel_thr) "0.30" set config(high_rel_model) "gpt-5.4" set config(mid_rel_model) "gpt-5.4-mini" set config(low_rel_model) "gpt-5.4-mini" set config(high_rel_words) "5000" set config(mid_rel_words) "10000" set config(low_rel_words) "0" set config(high_rel_chat_words) "3000" set config(mid_rel_chat_words) "3000" set config(low_rel_chat_words) "3000" set config(max_question_words) "1000" set config(embed_model) "text-embedding-3-small"
A high-relevance question is one with relevance greater than or equal to high_rel_thr. For high-relevance questions, the chatbot retrieves high_rel_words of documentation and up to high_rel_chat_words of recent chat history. It submits these to the high_rel_model large language model (LLM) for completion, along with the high_rel_assistant instructions and the question. A mid-relevance question has relevance greater than or equal to mid_rel_thr, but less than high_rel_thr. For mid-relevance questions, the chatbot submits mid_rel_words along with mid_rel_chat_words of recent chat history, the mid_rel_assistant instructions, and the question to the mid_rel_model. The configuration presented above has high-relevance questions being submitted to the "gpt-5.4" model along with 5k words of documenation and up to 3k words of chat history. Mid-relevance questions are handled by "gpt-5.4-mini" along with 10k words of documentation and up to 3k words of chat history in an effort to permit the model to answer a question that is relevant to our documentation but poorly-worded or ambiguous. Low-relevance questions are submitted to "gpt-5.4-mini" with no documenation and up to 3k words of chat history. We get at quick answer to an irrelevant question using the model's built-in knowledge.
We pay particular attention to the instructions we send to the answer generator. These instructions are often called the "prompt" in the jargon of retrieval-assisted generation. Here is the prompt we use with high-relevance and mid-relevance questions.
You are a helpful assistant for a technical support chatbot. The user’s question may be ambiguous or underspecified. If you have enough information from the reference documentation and chat history to answer the user’s question with confidence, then answer the question. Otherwise, use the reference documentation and chat history to compose a request for clarification in which you ask for specific information that will resolve the ambiguity of the question. Do not make up facts or fabricate plausible-sounding answers. It is better to ask for clarification than to provide inaccurate information. When answering the user's question: - Respond using Markdown formatting. - Summarize and explain technical documentation. - Complete mathematical calculations whenever possible. - If the question asks for a figure, graph, or image, and a relevant figure, graph, or image is available in the provided content, include the figure, graph, or image in your response using the format ``. - Provide at least one hyperlink to original documentation, and provide all hyperlinks using the format `[Descriptive Title](full_url)`. - When including configuration blocks, code samples, or structured text, always enclose them in triple backtick Markdown code fences. Do not output raw structured text outside of code fences. - Use LaTeX formatting for mathematical expressions. - Use the minimal escaping required to represent valid LaTeX. - Never use ```math blocks for LaTeX. Always use \(...\) or \[...\].
Here is the prompt we use for low-relevance questions. Depending upon the configuration of our RAG Manager, we may no documentation at all for answers to such questions. So we do not ask the chatbot to provide any hyperlinks.
You are a helpful assistant for a general-knowledge chatbot. When a user asks you a question, you will attempt to answer the question using your general knowledge. You will use the chat history to better understand the current question. Do not make up facts or fabricate plausible-sounding answers. If you are uncertain of your answer, tell the user that you do not know the answer. When answering the user's question: - Complete mathematical calculations whenever possible. - Respond using Markdown formatting. - Use LaTeX formatting for mathematical expressions. - Use the minimal escaping required to represent valid LaTeX. - Never use ```math blocks for LaTeX. Always use \(...\) or \[...\].
The answers we receive from the LLM are always in Markdown format, and any equations will be in LaTex. But all answers are enclosed in a JSON record to make sure they pass without corruption through the various text channels they must traverse on their way between the LLM and our chatbot display. The chatbot extract the LaTeX math and Markdown separately. It applies subsititutions to the raw LaTeX, and converts the Markdown into HTML. Our chatbot web interface renders the LaTeX equations using a JavaScript engine called MathJax.
[29-JUL-25] This chapter of our chatbot manual serves as the manual for our RAG Manager. The RAG Manager is a LWDAQ Tool available in the LWDAQ Tool menu starting with LWDAQ 10.7.2. The RAG Manager provides the routines we use at to support the OSI Chatbot. The acronym "RAG" stands for "Retrieval-Assisted Generation", where "generation" is the composing of an answer to a question by a completion endpoint, and "retrieval-assistance" is gathering exerpts relevant to the question from our documentation. In the jargon of retrieval-assisted generation, these exerpts are called "chunks". The chat web interface is provided by a PHP process running on our server and some JavaScript running on the client web browser. When the user provides a new question, the server calls LWDAQ to collect relevant chunks, submit them to the LLM, and wait for an answer. In the sections below, we explain how the RAG Manager works with OpenAI and the Chatbot interface to provide the OSI Chatbot functionality
The RAG Manager needs a directory to which it has read and write access in order to perform its function, in particular to store document chunks and their vector representations. We must specify a root directory for the manage to use. By default, this root directory will be set to "~/Active/RAG", which will almost certainly not exist on your system. Open the manager's configuration panel and press Set_Root to select a root folder. In order to embed chunks and complete questions, you will need an OpenAI application interface key, so that you can be billed for thes services. Store the key somewhere. Press Set_Key and select the key. Now press Save_Configuration to save your root directory and key file locations to a RAG Manager settings file. The next time you open the manager, these settings will be applied automatically. You will also need the Source_URLs button to make your own list of HTML documents for chunking. Save these in the same way.
[25-JUN-25] The key to retrieval-assisted generation is the ability of the LLM to represent the content of an chunk with a unit vector in an n-dimensional sphere. In the jargon of retrieval-assisted generation, the process of representing the syntactic meaning of a chunk as an n-dimensional vector is called "embedding", and the resulting vector is the "embedding vector". We use OpenAI's "text-embedding-3-small" service to embed our chunks. This service produces vectors in a 1536-dimensional space. We submit an chunk to the OpenAI "embedding end point" and receive in response 1536 numbers representing the components of the vector. If we sum the squares of all these numbers, we always obtain a result close to 1.00000, so we have concluded that the vectors are normalized at the source. Retrieval-assisted generation operates on the assumptioin that the angle between two embedding vectors that have similar meaning will be a small angle. In particular, if the angle between the embedding vector of a question and the embedding vector of an chunk is small, that chunk is relevant to the question, and should be used as a basis for answering the question.
We measure the proximity of two embedding vectors by taking their dot product. Because all embedding vectors are normalized before delivery, their dot product is equal to the cosine of the angle between them. Our measure of "relevance" for a chunk is the cosine of the angle between the chunk embedding vector and the question embedding vector. Two identical chunks have relevance 1.0. In principle a chunk could have relevance -1. With "text-embedding-3-small", we find that when the best chunk in our library has relevance 0.5 or greater, it is almost certainly a question about our products. If the relevance is between 0.3 and 0.5 is may be a question about our products, but if less than 0.3, the question is almost certainly or general question that cannot be answered by our chatbot library.
[25-JUN-25] Before we generate a new chunk libary, we must provide the RAG Manager with a list of URLs from which it should download the documents out of which it will create the library. The RAG Manager window, which appears when you open the RAG manager from a graphical instance of LWDAQ, provides a Source_URLs button in its Configuration Panel that allows you to define and apply a list of URLs. When the list is "applied" it is saved in the RAG Manager's internal array, but the URLs are not yet accessed. The pages we are going to download to make our chunk library are our "sources".
Once we have our list of URLs, we use the Delete button to delete the old library. All the chunks will be deleted, but none of the embedding vectors. Each chunk has two files on disk. One is the "content string", wich resides in the content directory, and the other is the "match string", which resides in the match directory. The embedding vectors are stored in the embed directory. The locations of these directories are set in the RAG Manager's configuration array. All three files corresponding to a chunk have the same name. All three are text files. When we delete the chunks, we delete the match and content strings, but not the embeds.
The sources we assume are HTML files. They must follow a strict format compatible with the RAG Manager. All our HTML files are hand-typed. We never generate them with any kind of website builder, nor will we create HTML from a word processor. We type our HTML by hand. All paragraphs are enclosed in p-tags like this:
<p>Text of paragraph.</p>
We are allowed to insert attributes into these and any opening tags. All tables are enclosed in <center>...</center> tags, with captions in the exact format <small><b>Table:</b>...</small>, like this:
<center> <center><table border cellspacing="2"> <tr> <th>Sample Rate (SPS)</th> <th>Active Current (μA)</th> </tr> <tr><td>64</td><td>27.2</td></tr> <tr><td>128</td><td>32.2</td></tr> </table><small>Table:</small> Active Current versus Sample Rate.</small> </center>
Figures can be in the same form as tables, but with <b>Figure:</b> in place of <b>Table:</b>. Or they can be in the form:
<figure> <img src="../HTML/HMT_Surgery7.jpg" width="100%"> <figcaption>HMT Implantation Surgery</figcaption> </figure>
Any retrival prompts must be inside the table or figure caption. Lists can be either ordered or unordered. Lists will be chunked together with their preceeding paragraph. Stand-alone equations made with HTML entities or with LaTeX math must be enclosed in a standaline block with equation-tags. For in-line equations, use HTML entities. You can use eq-tags with in-line LaTeX, but we recommend against in-line LaTeX. The LaTeX codes do not present syntactic meaning to text embedding, and so serve to dilute the precision of embedding. Instead of in-line LaTeX, use HTML entities. We use an h1 heading to provided the title of the document, h2 headings for "chapters", and h3 headings for "sections". Date codes in the form [dd-mmm-yy].
[25-JUN-25] We press Chunk to download our sources and divide them all into a single list of chunks. The RAG Manager uses "curl" to download the sources. The "curl" utility supports both https and http. We test the RAG Manager on Linux and MacOS, both of which are UNIX variants with "curl" installed. We do not test the RAG Manager on Windows. The RAG Manager proceeds one URL at a time, dividing each page into an initial sequence of chunks, and then combining some chunks with those before or after in order to bind things like equations to their explanatory text below, and lists to their explanatory text above. Check "Verbose" to see the notification and type of every chunk created. Check "Dump" and the manager will write all match and content strings to disk in a file called "dump.txt" in the log directory.
The first step in chunking an HTML document is to resolve all its internal hyperlinks into absolute URLs. We then convert them into Markdown format. We convert all HTML entities into unicode characters. The embedding and completion endpoints like Markdown. They like unicode in preference to HTML entities, so this conversion is to improve embedding and completion. Now we are ready to fragment the page. The RAG Manager has a list of HTML tags it uses to extract fragments from the page. This list is stored in the frag_tags element of the tool info array. The simplest fragment is a paragraph bounded by p-tags. We call this a p-field. The text within a field, but not including, the tags, we call the body of the field. We provide chapter and section titles with h2 and h3 fields. In addition to fragment extraction by tags, the RAG Manager looks for timestamps in the format [dd-mmm,yy], and whenver it finds them, it creates a fragement for these as well. Once it has all the fragments of a page, it sorts them in order of ascending first character index. Now we have a list of fragments in the order they appear in the text.
We go through the fragments and create a content string and a match string for the next chunk. We combine the current chunk with a previous chunk if the fragment type requires us to do so, or we instert the current chunk in front of the previous chunk if this is required. The "content string" includes a document title and hyperlink, chapter title and hyperlink, a section title and hyperlink if a section is defined, and a date timestamp if one has been supplied, as well as hyperlinks and table contents. The tables are written in a verbose Markdown format in which every table cell receives its column title. The "match string" is a best representation of the syntactic meaning of the content. If we accompany a table caption with one hundred numbers from the table itself, the embedding vector generated by the entire string does not capture the meaning of the caption, but is instead diluted into ambiguity by the presence of the numbers, which have little or no syntactic meaning. Hyperlinks and date stamps dilute the syntactic meaning, because they are not prose or equations. In the match string we say "Excerpt from document-name, chapter chapter-name, section section-name" followed by an empty line, and then the match string extracted from the chunk. Separate blocks of mathematical equations do not have a strong syntactic meaning for embedding, so we omit them from our match strings. But we include the paragraph following the equation, which we assume explains the equation and defines its variables. Furthermore, in our HTML document, we can add "prompt" fields like this:
<prompt>Use this table to calculate SCT or HMT operating life.</prompt>
The RAG Manager will include the bodies of these fields in the chunk's match string, but exclude them from the content strings. These fields are "retrieval prompts". When we add well-chosen retrieval prompts to the caption of a table or figure, we can greatly increase the likelyhood that the table will be retrieved for certain questions that require the numbers in the table. We may want to hide the prompt strings from the browser view of the HTML document, in which case we can do this:
<prompt style="display:none">What is an SCT?</prompt>
With the addition of the following lines to our cascading style sheet (CSS), we can omit the display:none attribute in prompt fields.
prompt {
display: none;
}
Now we can just write:
<prompt style="display:none">What is an SCT?</prompt>
Some documents are sparse but dense. Our implantation protocols, for example, consist of lists of concise instructions interspersed with photographs and tables. An entire protocol consists of under fifteen hundred tokens. Instead of dividing the document into separate chunks, we prefer to place the entire document into a single content string, and compose our own match string with retrieval prompts. To achive this end, we embed retrieval directives in the document by means of "rag" fields. These directives can be placed anywhere in the HTML page and affect the entire HTML page. Here is an example series of retrieval directives and prompts that results in a single chunk for the entire page, with a match string consisting only of a title and some questions.
<rag>page-chunk</rag> <rag>match-prompts-only</rag> <prompt>What is the procedure for implanting an HMT?</prompt>
Although the retrieval directives can be anywhere in the HTML page, the prompts must be placed within a document chunk somewhere in the pager. We have assumed, in the above HTML code, that we have added the following to our CSS so that the rag fields will not be visible to a browser.
rag {
display: none;
}
The "page-chunk" directive tells the RAG Manager to combine all chunks it extracts from the page containing the directive into one chunk. The content will be a concatination of all content chunks, but each content chunk will retain its chapter, section, and date titles. The match string will be the concatination of all the chunk match strings. Match strings do not contain chapter, section, or date titles.
The "single-chunk" directive is the same as page-chunk.
The "chapter-chunk" directive tells the RAG Manager to combine all chunks from a single chapter into one chunk. A "chapter" is the content following an h2-level title. The resulting content will consist of a single chapter title, with each section receiving its own section and date titles. The match string will be a concatination of all the match strings.
The "section-chunk" directive tells the RAG Manager to combine all chunks from a single section into one chunk. A "section" is the text following an h3-level title. The resulting content will consist of a single chapter, date, and section title followed by all the content chunks extracted from the section. The match strings will be the concatination of all match strings.
The "match-prompts-only" directive tells the RAG Manager to delete from each match string all content other than that provided by "prompt" fields. When used with page-chunk, chapter-chunk, or section-chunk, this directive combines all the prompts from a page, chapter, or section to form the match string for the entire page, chapter, or section.
The "omit-lists" directive tells the RAG Manager to discard all list fragments found in the current page.
The "summary-match" directive tells the RAG Manager to include the string "%%%%Summarize" at the top of the match string that we will later detect during our summarizing phase of chunking. The summarizing phase occurs after chunking and naming is complete, and does nothing unless there are match strings to which the summary-match string has been added. At that time, the RAG Manager replaces the match string with a summary of the match string. We use this directive in conjunction with chapter-chunk when chunking novels, diaries and other documents that are neither dense nor technical, but contain both dialog and exposition. To summarize a match string, the RAG Manager uses the summary_model to compose a summary in accordance with the instructions contained in the summarize_prompt. The command to summarize is a brief sentence in the summarize_question. Summarizing a 2000-word chapter with gpt-5.4-mini takes several seconds, so the RAG Manager first checks to see if a summary for this match string already exists. Repeated summaries of the same match string will be slightly different, but the RAG Manager names the chunk after its original match string, not the summarized match string, so when we come to summarizing the exact same match string, we will be able to find the summary on disk, if it exists. If no summary exists, we create one. By this means, we create new summaries only when we need to. We see that this process for avoiding repeat-summarization of the same string requires that the chunks each be named already, which is why summarizing takes place after chunking is complete.
Once we have all the match and content strings produced by a single page, the RAG Manager passes the match string to "openssl" to obtain a unique twelve-digit hexadecimal name for the chunk, something like "6270ebd71f0b". This name is a signature of the match string. The probability that two different match strings in our library will have the same signature is next to zero. We use the signature of the match string instead of a signature of the content string because it is possible for the content string, indeed for all the content strings, to change while the match strings remain identical. We might apply a bulk edit on our website, changing a hyperlink everywhere it occurs. The content strings all change, but the match strings do not, because they do not contain hyperlinks. We should not have to re-embed the match strings, because they have not changed. So we use the original match string for the signature. Each chunk now consists of a match string, a content string, and a name string.
Once we have all the pages chunked, we have our complete library of chunks, each consisting of a match, content, and name string. The match string may be the original match string or a summarized match string, but the name will always be the signature of the original match string. Now we store the content and match strings to disk. With our contents strings and match strings saved to disk in separate directories, each string with a unique name particular to the chunk, our chunk library is complete.
[25-JUN-25] Now that we have the content and match strings, we are ready to embed the match strings. We press "Embed". The manager goes through all the match strings and checks to see whether an embedding vector exists for that match string. The embedding vector, if it exist, will reside in the embed directory and share the same name as the match string. If an embed exists, the chunk is ready to deploy. If no embedding vector exists, the embedder submits the match string to the OpenAI embedding endpoint, obtains the match string embedding vector, and writes the match string embedding vector to disk in the embed directory. To obtain the vector, we need an API Key, which is the means by which we identify ourselves to OpenAI and agree to pay for the embedding service. Embedding is inexpensive. At the time of writing, the "text-embedding-3-small" embedding model costs two US cents per one million input tokens, where a "token" is four characters. One thousand chunks, each one thousand tokens long, will cost a total of two cents to embed.
With embedding complete, we have a library of content strings and embedding vectors ready for retrieval-assisted generation. Note that we have not removed obsolete embedding vectors from the embed library. By "obsolete" we mean any vector for which there is no corresponding content string. When we want to purge obsolete vectors, we use the Purge button. There is no particular rush to purge obsolete vectors. When we retrieve a list of content strings most relevant to a question, any content string that does not exist we will skip over. But if obsolete embedding vectors start to outnumber our active vectors, retrieval will be less efficient.
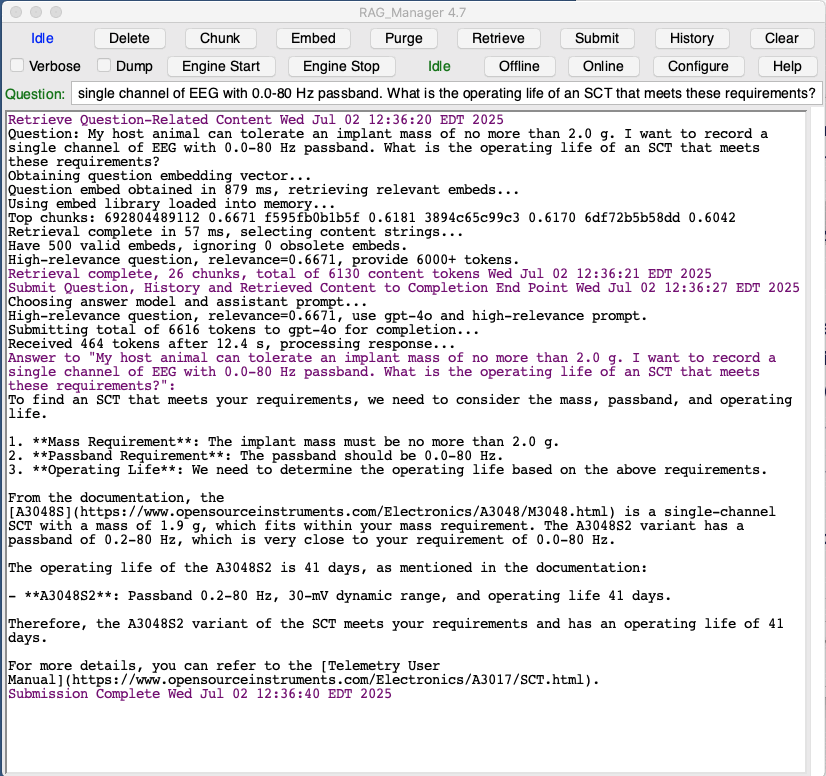
[26-JUN-25] Now that the library is complete, we are ready to retrieve content strings relevant to a question. To ask a question, we enter a question in the question entry box and press Retrieve. The first time we do this after chunking, the manager will load the library into memory, which will take a few seconds. It loads all embedding vectors in the embed directory into memory. Each embed takes up 8 KByte on disk and 12 KByte in memory. On disk, we store the embedding vector components as integers, having multiplied their original real-valued components by embed_scale. Saving them as integers makes the disk files more compact and easier for us to examine. In memory, we convert back to real-valued components. Each component is an eight-byte real number, which is slightly larger than the original text-format integer value.
With the embed library loaded into memory, the retrieval will proceed to finding the most relevant chunks. The RAG Manager fetches the embedding vector of the question from the embedding end point and compares it to every embedding vector in its list. It sorts the embedding vectors in order of decreasing relevance. We use the relevance of the first chunk as our measure of the relevance of a question to our chunk library. We determine if the question is high, mid, or low-relevance. We set a limit on the number of content tokens we will submit to the completion endpoint based upon the relevance of the question. The default configuration of the manager right now assigns low-relevance questions get no documentation at all, mid-relevance questions 12000 tokens of documentation, and high-relevance questions 6000 tokens. The manager reads content strings from disk, starting with the content string of the most relevant chunk, and proceeds through its list. When the total number of tokens passes our limit, it stops adding content. If chat_submit is greater than zero, the manager adds the most recent chat_submit exchanges from the chat history to the submission data as well. By default, we add the previous three exchanges to to give continuity to the chat.
We select content strings using the embedding vectors of the match strings. When we select a table of numbers, we select it based upon its match string, not the numbers themselves. The match string could be the table caption, or it could be the table caption combined with some retrieval prompts we embedded in the source HTML document. With the match-prompts-only directive, we will be matching only on prompts: even the table caption will be removed from the match string. But what we submit to the completion end point is the entire table with its caption. The LLM does well understanding and making use of tabulated numbers, especially if they are supplied with repeating column titles on every line and in Mardown format. The LLM has no trouble understanding URLs in Markdown format, and it can understand our chapter, section and date titles as well. It can also understand LaTeX math equations.
At the end of retrieval, we have all the content strings ready to send to the completion endpoint. With the verbose flag set, we get to see all the content strings and the chat history printed in the manager's text window. If we set the show_matches flag, we will see in place of the content strings the match strings used to make the embedding vectors.
[26-APR-26] Once retrieval is complete, we press Submit and the RAG Manager combines the assistant prompt, the documentation chunks, and the question in one big json record. It submits this record to the OpenAI completion endpoint and waits for an answer. For high-relevance questions, we use a completion model with thorough and detailed reasoning powers. But this model is slow, so we must limit the amount of documentation we submit with our question. For mid-relevance questions, we submit to a faster but less powerful model along with more documentation. For low-relevance questions, we submit no documentation at all, but we submit more chat history. The low-relevance questions either have nothing to do with our documentation, or are written in a foreign language, so we submit to the fast, cheap service just to provide some kind of answer, in the interests of being polite to the user.
The answer we receive from the completion endpoint will take a form, tone, and level of detail controlled by our assistant prompt. Our default promp instructs the endpoint to give us answers in Markdown, with equations in LaTeX. The gpt LLMs understand Markdown and LaTeX very well, these being the native formats upon which they were trained. When it comes to producing answers, Markdown and LaTeX are their preferred output formats, so we instruct the LLM to produce Markdown and LaTeX. The answer we receive from the LLM is wrapped in a JSON container, so we have to extract the answer, translate the many characters escaped for JSON, so as to recover the original Mardown and LaTeX. This we do in the manager's get-answer routine.
[02-JUL-25] The RAG Manager provides Delete, Chunk, Embed, and Purge buttons to create a library of content strings, match strings, and embedding vectors. The Retrieval button loads the embedding vector library, retrieves the most relevant content string names, and selects the most relevant until it fills its token quota for submission. The Submit button submits the question to a completion end point. These functions serve us well during development and testing of our chunk library. When we deploy the library, however, we will have a browser-based front end, probably consisting of a couple of PHP scripts, that accepts a user question and calls the RAG Manager to provide an answer. In this case, the most robust way to provide the answer is to launch a new, non-graphical instance of LWDAQ from the PHP chat handler, and have this new process perform the retrieval and submission. But we want to avoid requiring that this instance load the entire embedding vector library into memory, because this will take several seconds, and delay submission. The RAG Manager provides a Retrieval Engine to provide retrieval for other LWDAQ processes.
In the RAG Manager, the Engine Start and Engine Stop buttons start and stop the retrieval engine. When the engine starts, it loads the embedding vector library into memory. The engine uses a file called signal.txt in the log directory to signal whether or not it is running. It updates the modified time of this file every few seconds. It watches for some other process to write a file named like Qx.txt, where x is a six-digit number. This file should contain the embedding vector of a question. The engine renames the file, reads the file, and deletes the file. It retrieves five hundred relevant chunk names, in order of descending relevance, and writes their names and relevances to a file called Rx.txt, where x is taken from the original embedding vector file name.
Meanwhile, the RAG Manager's Retrieve function looks for the signal file and checks to see if an engine is running. It so, it writes the embedding vector file Qx.txt, generating x at random, and waits to see if it gets a retrieval list. If one appears, it reads the list and uses the list to retrieve chunks. If none appears, it loads the embedding library and performs the retrieval entirely on its own.
The retrieval engine looks for a file called offline.txt in the log directory, which will contain a UNIX timestamp of the time when the chatbot and engine should go offline. If this file is present, the engine does not perform retrieval, because the assumption is that the embedding vector library is being rebuilt, and is not currently available. As soon as the offline.txt file disappears, the engine re-loads the library.
The RAG Manager Retrieve function also pays attention to the offline.txt file. When it sees this file, it does no retrieval. The RAG Manager Submit function looks for offline.txt as well, and if it sees the file, it returns a "Chatbot Offline" message, which includes a report of when the chatbot went offline, and when we expect it to be on-line again.
We can start and stop a retrieval engine in the RAG Manager using the Engine Start and Engine Stop buttons. We can take the chatbot offline and put it back online again with the Offline and Online buttons. To run a retrieval engine in the background as a daemon on our web server, we run LWDAQ in no-console mode, with a terminal command something like this:
./lwdaq --no-console ../RAG/engine_config.tcl
You will fine engine_config.tcl in Chat_Scripts.zip, along with gen_config.tcl and chat_config.tcl. To update the on-line chunk library, we pass a generator script into LWDAQ to perform the delete, chunk, embed, and purge, along with going offline at the start and online at the end.
./lwdaq --no-gui ../RAG/gen_config.tcl
As the re-generation of the library proceeds, the retrieval engine and the chatbot will go offline automatically. When it completes, the retrieval engine will come on-line again and so will the chatbot. The chat-handler itself will call lwdaq with another configuration script, and pass into it the question and chat history:
./lwdaq --no-gui ../RAG/chat_config.tcl $QUESTION $HISTORY
If the above process sees that the chatbot is offline, it returns the offline message. If the completion endpoint times out, it returns a "Lost Train of Thought" message. When all goes well, it returns an answer. If there is no retrieval engine, it will take several seconds longer to submit the question.
[21-JUL-25] If you happen to have your documentation on-line as hand-typed HTML, and you follow the rules presented above for paragraphs, tables, figures, equations, and lists, setting up a chatbot of your own using our open-source RAG Manager and OpenAI's embedding and completion endpoints will be straightforward. We appreciate, however, that you are unlikely to have your documentation arranged as hand-typed HTML. Hardly anyone does. You may have a lot of your documentation saved as PDF files. If so, you could export them from PDF to HTML and try chunking the result. It is very likely that you have HTML pages generated by a web authoring program of some sort. These pages will contain a great deal of style and formatting instruction, and we think it unlikely that our existing chunking algorithm will be able to handle such complex HTML paragraphs and tables. Nevertheless, let us suppose, for the sake of argument, that you are able to put your essential user documentation somewhere on your website in HTML documents simple enough for our RAG Manager to parse. If you can do that, then setting up a chatbot of your own will be straightforward, provided you have control over your server machine.
The OSI Chatbot runs on the OSI web server. The web server is a Linux machine. Setting any other chatbot on another Linux machine will be straightforward, but you must have control over the Linux machine so you can use PHP to launch short-lived processes, and use the terminal to launch a long-running retrieval engine daemon. The schematic below shows how the various parties involved in the chatbot interact. The chatbot user accesses the chatbot with a browser. For the purpose of this discussion, the chatbot is the process that interacts with the user, embeds the question, obtains a list of relevant content strings from the retrieval engine, and submits a content package to the completion end-point. The chatbot is implemented in PHP using chat.php and chat-handler.php, which you will find in Scripts.zip, along with the configuration scripts we mention in the remainder of this chapter. The chat-handler uses the PHP shell_exec command to run the RAG Manager. It configures the RAG Manager with chat_config.tcl. It passes into the RAG Manager the question and the most recent entries in the chat history.

On the server we have a Retrieval Engine running. This process is a LWDAQ process with no console. It runs in the background. We configure the engine using engine_config.tcl. We start LWDAQ, open the RAG Manager, and start the retrieval engine with the following terminal command. Note that we have installed our LWDAQ in the directory /opt/custom/LWDAQ and our RAG directory structure in /opt/custom/RAG. These RAG folders should be outside the website HTML document structure, because they contain logs and keys.
/opt/custom/LWDAQ/lwdaq --no-console /opt/custom/RAG/engine_config.tcl -log
To generate the match strings, content strings, and embed vectors, we use a generation process configured by gen_config.tcl. This process lists all the web pages we want to chunk, and performs the chunking. We run this process occasionally and manually, when we want to implement updates to our documentation. We currently have 3600 chunks. An update that requires fifty new embedding vectors will take a couple of minutes on our server. During this update, the chatbot will be disabled, because it will be checking the disable flag file in the log directory. We run the generator with the following terminal command.
/opt/custom/LWDAQ/lwdaq --no-gui /opt/custom/RAG/gen_config.tcl
Because the chatbot is calling the RAG Manager to perform retrieval and submission, it maintains a log of questions and answers in a log file in the log directory. Likewise, the retrieval engine maintains a log file. The retrieval engine keeps using the same log file until we stop it or we restart the server operating system. But the chatbot uses a new log file every day to make it easier for us to keep track of new questions.
[26-MAY-26] The embedding endpoint does not embed images. It embeds only text. It greatly prefers Markdown for prose, tables, and lists. It likes LaTeX for mathematical equations. We translate our documentation chunks from HTML and LaTeX into Markdown and LaTeX. Our RAG Manager embeds figure captions. Captions should give a specific and unique description of what is in an image. Add RAG "prompt" fields containing questions that would benefit from the answer displaying or linking to the image.
We do not send the content of tables to be embedded. They will not participate in retrieval. Only the table captions participate in retrieval selection. Make table captions specific and unique. Add RAG "prompt" fields to increase relevance to questions that would benefit from the contents of the table being retrieved for submission.
We completion endpoint does not accept images. The large language model (LLM) we are using does not follow hyperlinks. It does not load images to which we send hyperlinks. Even if it did load images, it would be unable to read text from the images or understand any of the information the image contained. To the completion endpoint, images are meaningless blobs. If, at any point, the LLM claims that it has understood something from an image, do not believe it. This claim is an LLM hallucination.
To support retrieval-assisted generation, provide tables of numbers, mathematical equations, and verbal descriptions of the information contained in images. The retrieval process does allow us to identify images that the human reader will benefit from seeing, but no information in an image will be available to the LLM unless we describe or duplicate that information in prose.
Use HTML entities for in-line mathematical expressions. These entity-based expressions have syntactic meaning for embedding. Do not use inline LaTeX expressions, because these do not have a clear syntactic meaning for embedding. We want our embedding vectors to be precise and based upon the prose contained in the match string. Block equations, which stand on their own within "equation" tags, can be in LaTeX. In fact, we encourage the use of LaTeX in block equations because the LLM understands LaTeX very well, even though the embedding vectors do not. Block equations will be included in the content strings that are retrieved, but they will be omitted from the match strings used to select content strings.
Do not use HTML entities "÷" and "×" in your inline mathematical equations. These are not well-understood by the LLM. Use "/" and "·" or "*". These symbols lend themselves to precise embedding. Separate the division and multiplication symbols from letters and numbers with a space. The space makes the syntax of the equation clearer to the embedding and LLM. You may prefer, in your original documentation, to use "÷" and "×", but the RAG Manager does not replace these with "/" and "*". It replaces the HTML entities with the unicode characters to which they correspond. We want to preserve these symbols so that we can write statements like "×10 gain" and "÷10 attenuator".